Детерминированные метрики для оценки LLM в DeepEval
В этой статье разбираем, как устроена детерминированная оценка моделей искусственного интеллекта в DeepEval, какие бывают метрики для тестирования LLM, какие подходят для RAG-пайплайнов и суммаризации. А также почему DAG-метрика DeepEval делает тестирование моделей ИИ более точным и прозрачным и в чем ее отличие от классического подхода к оценке качества нейросетей, который не работает в сложных сценариях.

Перевод: How I Built Deterministic LLM Evaluation Metrics for DeepEval
DeepEval — это open-source фреймворк для оценки качества ответов LLM. Все метрики в нём построены на принципе LLM-as-a-judge. Проект вырос до почти полумиллиона установок в месяц и около 5 000 звёзд на GitHub. Сейчас инженеры запускают в нём более 800 тысяч оценок в день и используют его для тестирования LLM-приложений, включая RAG-пайплайны, агентов и чат-ботов.
Основатель DeepEval провёл несколько созвонов с пользователями и заметил чёткое разделение: одни были полностью довольны встроенными метриками, другие — нет.
Пользователи, которых не устраивали метрики, называли две простые причины: метрики не подходили под их сценарии и не давали достаточно детерминированных результатов и не обеспечивали стабильной детерминированной оценки LLM, поскольку все оценки выполнялись через LLM-as-a-judge. Это серьёзная проблема: ключевая задача DeepEval — избавить инженеров от необходимости разрабатывать собственные метрики и пайплайны для оценки. Если встроенные метрики всё равно приходится заменять своими, то смысл продукта теряется.
Это привело команду к важному вопросу: как сделать встроенные метрики DeepEval достаточно гибкими и детерминированными, чтобы клиентам больше не приходилось создавать свои?
Спойлер — решение выглядит примерно так:
Проблема с пользовательскими метриками для оценки LLM
По умолчанию в DeepEval используются такие метрики качества ответа LLM, как contextual recall, релевантность ответа, корректность ответа и другие — то есть критерии более общего характера и относительно стабильные. Именно «относительно», потому что большинство этих метрик основаны на технике question-answer-generation (QAG). Поскольку QAG сводит итоговый вердикт к бинарному «да» или «нет» для закрытых вопросов, пространство для стохастичности там минимальное.
Такие метрики, как релевантность ответа, по своей природе довольно широкие — по сути это оценка качества ответа нейросети. Сложно определить релевантность в абсолютных терминах, но пока метрика даёт внятное объяснение, большинство пользователей воспринимают её нормально. Ещё одна причина, по которой эти метрики работали хорошо, — наличие чётких и прозрачных формул. Нравится метрика или нет — обычно зависело от того, согласен ли человек с алгоритмом, который лежит в её основе.
Например, contextual recall оценивает работу ретривера в RAG-пайплайне и используется как базовая RAG retriever evaluation метрика. Она определяет, достаточно ли извлечённых текстовых фрагментов для того, чтобы LLM смог выдать ожидаемый идеальный ответ. Алгоритм был простым и интуитивным:
- Извлечь все атрибуты, которые присутствуют в ожидаемом ответе, используя LLM-судью.
- Для каждого атрибута определить, можно ли вывести его из контекста ретривера — набора текстовых узлов. Для этого снова используется LLM-судья и техника QAG, где результат по каждому атрибуту — строго «да» или «нет».
- Финальная оценка contextual recall — доля ответов «да» от общего количества.
Алгоритм был простым, понятным и интуитивно верным — именно так и должна работать метрика recall. И поскольку на втором шаге LLM-судья давал строго бинарные ответы, оценка оставалась достаточно стабильной для любого тестового кейса.
Но проблема возникла, когда команда начала разбираться с кастомными метриками проверки качества нейросетевых ответов с условной логикой и многоэтапными проверками. Было очевидно: стандартных метрик недостаточно для полноценных, специфичных под задачу оценок.
Под пользовательскими критериями понимаются случаи, вроде:
«Проверьте, что вывод представлен в формате Markdown. Если да — убедитесь, что все заголовки разделов присутствуют. Если присутствуют — проверьте, что они идут в правильном порядке. После этого оцените качество самого резюме».
Такой тип оценки принципиально другой — фактически это структурированная оценка LLM, где логика разбита на этапы. Речь уже не просто об определении качества, а о выполнении многошагового процесса с условной логикой, где каждый шаг добавляет новый уровень сложности.
Внутри команды мы стали называть более простые критерии вроде «является ли это хорошим резюме?» игрушечными (toy criteria). В таких случаях не требовалась по-настоящему детерминированная оценка, и для них у нас уже был GEval — SOTA-метрика для оценки пользовательских критериев через CoT-подсказки в парадигме «заполнения формы». Пользователи могли донастроить формулировки своих критериев, делая метрику более мягкой или более строгой, но когда у вас есть конкретный сценарий, например суммаризация, и нет тысяч тест-кейсов для получения статистической значимости, вам нужна детерминированная оценка. Для большинства пользователей это было критично: в таких случаях недостаточно опираться на расплывчатые субъективные суждения — оценка должна давать стабильные, надёжные показатели, которым команда может доверять как отражению реальной производительности.
И это возвращает нас к пугающим кодовым базам: сотни строк, посвящённых тому, чтобы вручную подстроить и выстроить логику оценки — только ради того, чтобы метрики хоть как-то работали под конкретные сценарии.
Поиск повторяемого решения для всех
Осознавали это пользователи или нет, по сути они строили дерево решений на базе LLM. Каждый шаг их процесса оценки был узлом, где LLM принимала решение или извлекала нужные атрибуты, а результат определял, что происходило далее. Если ответ проходил одну проверку — он переходил к следующей. Если не проходил — логика выставления оценки менялась соответствующим образом.
Это и объясняло, почему их код выглядел именно так: длинные цепочки вызовов LLM, вложенные условия, наборы правил — всё ради того, чтобы обеспечить структурированную, пошаговую логику оценки. И хотя было очевидно, что пользователям действительно нужен такой уровень контроля, было так же очевидно, что писать и поддерживать эту логику вручную — мучительно.
Интересно, что некоторые пользователи уже встраивали GEval в свои DAG-процессы — не для полноценной оценки, а как лёгкий механизм предварительных проверок «пройти / не пройти» перед переходом к следующему шагу. Иногда цель заключалась не в том, чтобы выставить детальный балл, а лишь в том, чтобы убедиться: ответ соответствует минимальным требованиям, после чего можно запускать более глубокую оценку.
Это ещё раз подтверждало наблюдение команды: пользователям нужна гибкость в построении собственных схем оценки, и единая универсальная система скоринга здесь не работает.
Команда DeepEval пришла к выводу, что пользователям нужен простой способ собирать DAG-структуры. Анализ показал, что для этого требуется четыре типа узлов:
- Узлы предобработки — преобразуют тестовые кейсы в удобные форматы для оценки (входы модели, выводы модели, ожидаемые ответы и т. д.).
- Узлы бинарных решений — принимают вердикты «да» или «нет» (как в QAG) на основе контекста, который поступает от родительских узлов.
- Узлы небинарных решений — возвращают один из нескольких строковых вариантов, также опираясь на контекст родительских узлов.
- Листовые узлы — выдают жёстко заданный балл или запускают GEval для вычисления оценки на основе вердикта родительского узла (например, если родитель — бинарный, то вердикт будет «да» или «нет»).
Так мы и выпустили метрику, основанную на этих четырёх типах узлов, и назвали её Deep Acyclic Graph metric — DAG.
Детерминированные, управляемые LLM деревья решений
DAG-метрика не только настраиваемая, но и полностью детерминированная, построенная вокруг деревьев решений, управляемых LLM, — это даёт прозрачность и полный контроль над процессом оценки.
Сильная сторона встроенных метрик DeepEval всегда заключалась в следующем: они разбивают тестовый LLM-кейс (в котором есть входные данные, фактический вывод модели, ожидаемый вывод и др.) на атомарные элементы, а вердикты LLM-судьи — на строгие бинарные ответы через QAG. Это снижает вероятность галлюцинаций и даёт более тонкий контроль на каждом шаге за счёт возможности передавать собственные примеры для in-context learning.
Мы взяли этот принцип и перенесли его в DAG-метрику, структурировав процесс оценки вокруг четырёх типов узлов:
- Task nodes — разбивают тестовый кейс на атомарные элементы.
- Binary Judgment nodes — принимают решения True/False и переходят к следующему узлу на основе исходного кейса или результатов родительских узлов.
- Non-Binary Judgment nodes — возвращают один из нескольких строковых вариантов, также основываясь на кейсе или данных от родителей.
- Verdict nodes — выдают финальную оценку: фиксированную или рассчитанную через GEval по итогам всего пути оценки. (Все листовые узлы — это verdict nodes; verdict node не может быть корневым.)
Самый показательный сценарий на практике, — оценка суммаризации LLM, особенно для структурированных документов: юридических контрактов, медицинских записей, транскриптов встреч. Такие summary должны следовать строгому формату, содержать обязательные секции в корректном порядке и сохранять качество и полноту. Каждый шаг такого процесса идеально ложится в узел DAG.
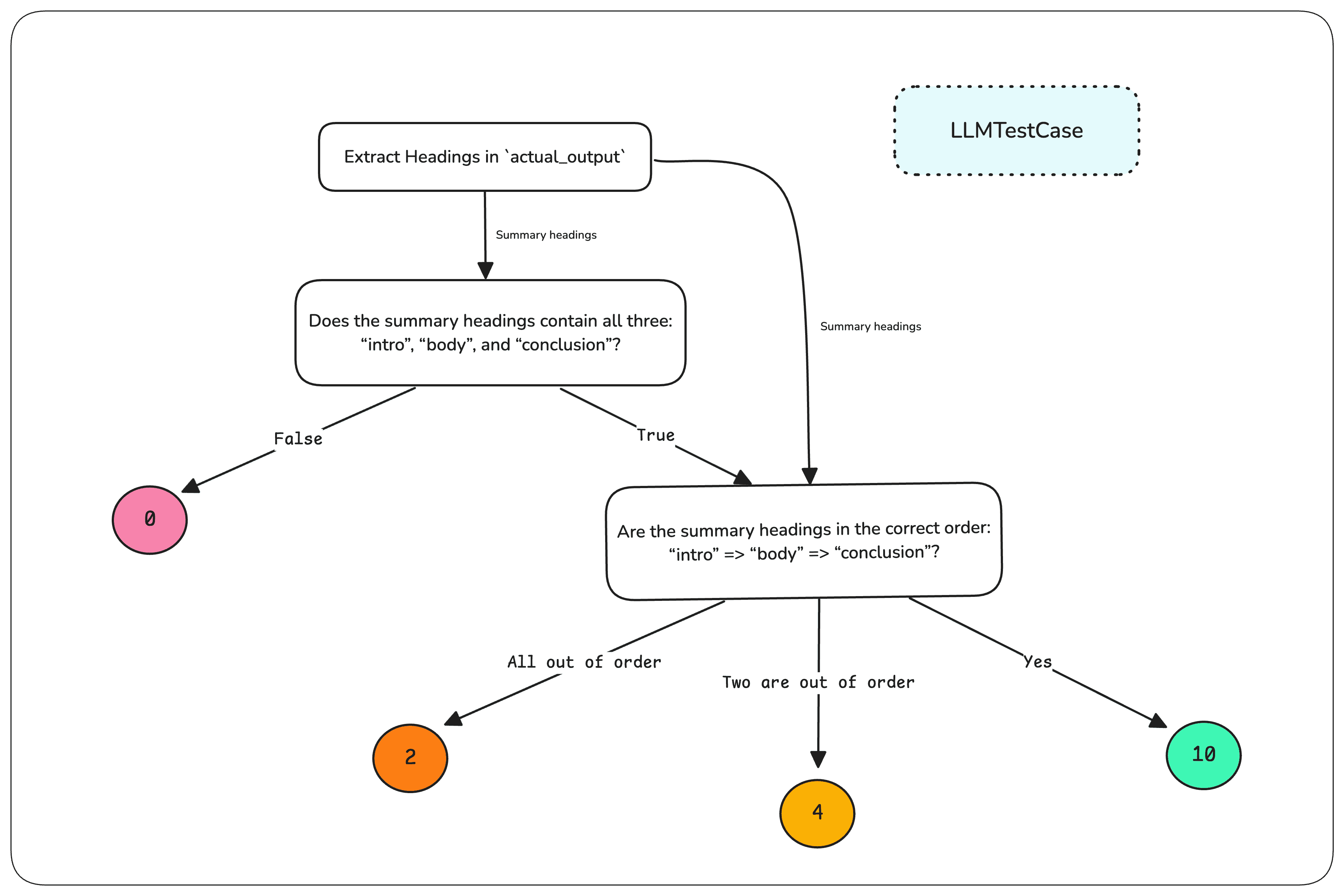
Пример: нужно оценить summary по встрече, которое обязательно должно включать три секции в правильной последовательности: Intro, Body и Conclusion. С DAG-метрикой вы можете:
- Определить task node как корневой, чтобы извлечь заголовки разделов в summary.
- Добавить binary judgment node, который проверит, корректны ли сами заголовки.
- Если заголовки корректны, использовать non-binary judgment node, чтобы определить, в правильном ли они порядке (или наоборот — насколько этот порядок нарушен).
- По итоговому пути DAG возвращает разный финальный скор.
Это закрывает весь объём логики, который раньше приходилось вручную собирать в сложный кастомный пайплайн оценки.
С DAG-метрикой DeepEval всё это теперь можно реализовать в нескольких строках кода — без ручной оркестрации, с сохранением структуры и полной детерминированности процесса.
Пространство применений ещё огромное, включая интеграцию G-Eval прямо в DAG-граф.
Вишенка на торте — неожиданные преимущества DAG-метрики
Помимо решения основной проблемы, DAG-метрика дала и несколько неожиданных преимуществ.
Одинаково эффективна даже для оценки более слабых моделей LLM
Многие пользователи предпочитают свои собственные модели для оценки, но в традиционных метриках вроде GEval слабые модели часто дают нестабильные результаты. Раньше приходилось либо:
- дообучать отдельную модель,
- либо загружать промпт десятками примеров.
Но в DAG-метрике пользователи сами управляют разделением оценки на мелкие шаги. Это делает процесс посильным даже для небольших и слабых моделей.
Использует все преимущества экосистемы DeepEval
Поскольку DAG полностью интегрирован в DeepEval, он автоматически получает:
- оптимизированное параллельное выполнение — task nodes на одном уровне работают параллельно;
- эффективное управление затратами — не нужно вручную следить за API-запросами;
- встроенное кэширование — повторное использование ранее вычисленных результатов;
- обработку ошибок — любые сбои поднимаются наверх для отладки; при необходимости их можно игнорировать, чтобы не останавливать всю оценку.
Отладка DAG-графов на новом уровне
Чтобы понимать, почему тест прошёл или провалился, важна прозрачность — по сути это отладка моделей ИИ в процессе оценки. В режиме verbose_mode DAG-метрика:
- выводит полный путь оценки — можно проследить каждый шаг;
- показывает промежуточные решения — легко понять, где тест «упал»;
- даёт контекст на каждом этапе — видно, что нужно скорректировать.
DAG-метрика не просто улучшает качество оценки — она делает весь процесс прозрачным, эффективным и адаптивным, независимо от того, какая LLM используется.
Заключение
В итоге DAG-метрика упрощает оценку качества моделей ИИ и делает тестирование LLM более надёжным и прозрачным.
Остальные метрики либо дают слишком мало контроля (как GEval, который плохо работает со слабыми моделями), либо требуют больших усилий: сложной оркестрации, ручных цепочек логики и точной настройки подсказок.
DAG-метрика решает эту проблему и формирует полноценную систему оценки LLM, которая работает быстрее и надёжнее: она разбивает оценку на структурированные детерминированные шаги, позволяя даже небольшим моделям работать стабильно и открывая простор для тонкой кастомизации.
Полностью встроенная в DeepEval, DAG-метрика работает значительно быстрее любых самодельных пайплайнов: автоматически параллелит выполнение, отслеживает стоимость, кеширует результаты и даёт детальную отладку — убирая всю операционную сложность построения своей системы оценки.