Оптимизация и автоматизация обработки счетов в Uber с помощью искусственного интеллекта GenAI
В современном бизнесе скорость и точность операционных задач и обработки документов напрямую влияют на эффективность компании. Для Uber, который работает с тысячами поставщиков по всему миру, одной из главных задач стала ежедневная обработка огромного объёма счетов. Этот процесс критически важен для финансовой деятельности компании: от него зависит корректность расчётов с контрагентами. В этой статье Uber делится опытом внедрения искусственного интеллекта в корпорациях: автоматизация обработки счетов с помощью generative AI (GenAI).
Перевод: Advancing Invoice Document Processing at Uber using GenAI
Предпосылки: ограничения RPA и необходимость внедрения ИИ в корпорациях
Традиционные подходы к invoice processing в корпорациях — ручной ввод данных, RPA и Excel — не справляются с масштабом. Для CTO и CIO это типичный вызов при автоматизации финансовых процессов с помощью ИИ.
Чтобы решить эти проблемы, Uber внедрили систему автоматизированной обработки счетов на базе GenAI. Она использует методы машинного обучения и обработки естественного языка (NLP), снижая объём ручной работы и автоматизируя процесс. В результате появилась масштабируемая и надёжная система, которая ускоряет обработку, сокращает число ошибок и делает работу удобнее.
Общий процесс закупок
Uber работает с внешними поставщиками товаров и услуг. Сначала поставщик подключается к системе по установленным правилам. Затем сотрудники Uber оформляют заказ на закупку (PO, Purchase Order). Поставщик выставляет счёт за товары или услуги в рамках этого заказа. После отправки счёт проходит согласование, и только потом производится оплата. Обязательное требование — счёт должен быть в формате PDF.

Процесс отправки счетов
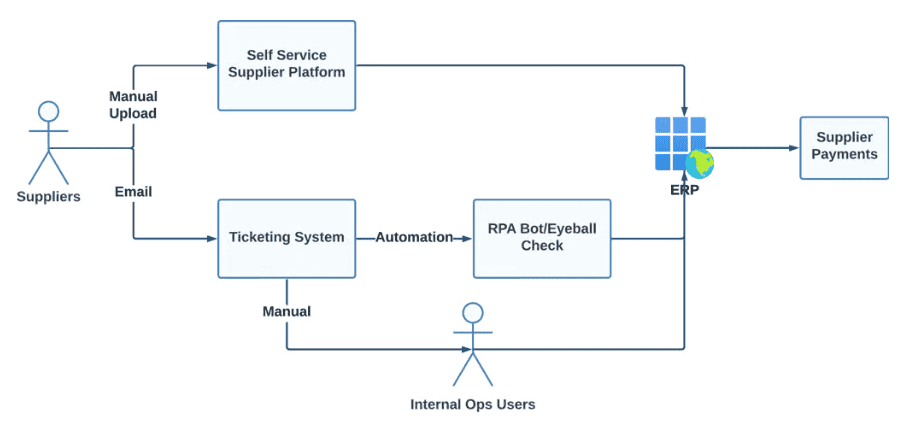
В рамках цифровой трансформации закупок Uber использует два канала для работы с поставщиками: платформу самообслуживания и email-интеграцию с ERP.
1. Платформа самообслуживания. Uber разработал внутренний сервис, где поставщики находят свои заказы и прикрепляют к ним счета.
2. Электронная почта. Счета можно отправить на специальный email-адрес. Такие письма попадают в тикет-систему: для каждого счёта создаётся отдельный тикет по заданным правилам. Дальше счёт проверяют RPA-боты (включая визуальную проверку) или сотрудники вручную. После проверки данные передаются в ERP-систему.
Основные сложности invoice processing и цифровой трансформации закупок
Бизнес-проблемы
Даже при внедрении корпоративных систем на базе RPA компании сталкиваются с ограничениями: высокая доля ручного труда, ошибки и рост затрат.
Среднее время обработки одного счёта (AHT) остаётся высоким, что вызывает задержки. Участие человека увеличивает риск ошибок, из-за которых возникают финансовые несоответствия и сложности со сверкой.
Для технических директоров это подтверждает необходимость перехода к ИИ для обработки счетов и документов.
Технические проблемы
Uber работает с тысячами поставщиков, у каждого свои шаблоны и форматы счетов. Документы могут быть на 25+ языках, содержать рукописный текст или сканы, что усложняет распознавание. В среднем счёт включает 15–20 ключевых полей и таблицы, которые нужно извлекать с высокой точностью. Дополнительные трудности создают многостраничные документы.
Ограничения старых инструментов
Ранее Uber использовал системы на основе правил (RBS) и RPA. Они подходили для ограниченного числа шаблонов, но перестали справляться при росте объёмов и появлении новых форматов. Каждое изменение требует ручной настройки правил. Такие решения плохо масштабируются, часто дают ошибки и требуют постоянного обслуживания.
Архитектура AI-платформы для автоматизации документооборота
Автоматизированная система обработки счетов на базе GenAI, внедрённая в Uber, строится на принципах точности, масштабируемости и гибкости.
Ключевые принципы:
- Точность. Система использует обученные модели машинного обучения и GenAI, которые позволяют корректно извлекать данные из счетов различных форматов. Это значительно снижает количество ошибок и повышает надёжность финансовых данных.
- Масштабируемость. Система способна обрабатывать большой объём счетов, поддерживая глобальные операции Uber. Благодаря устойчивой архитектуре и современным технологиям, она масштабируется без потери производительности.
- Гибкость. Решение адаптируется к новым форматам счетов без необходимости ручной настройки правил. Это особенно важно в условиях постоянного изменения форматов и разнообразия поставщиков.
- Удобство для пользователей. Особое внимание уделено разработке интерфейса, упрощающего проверку и корректировку данных. Интуитивно понятный и доступный функционал позволяет сотрудникам эффективно управлять процессом обработки.
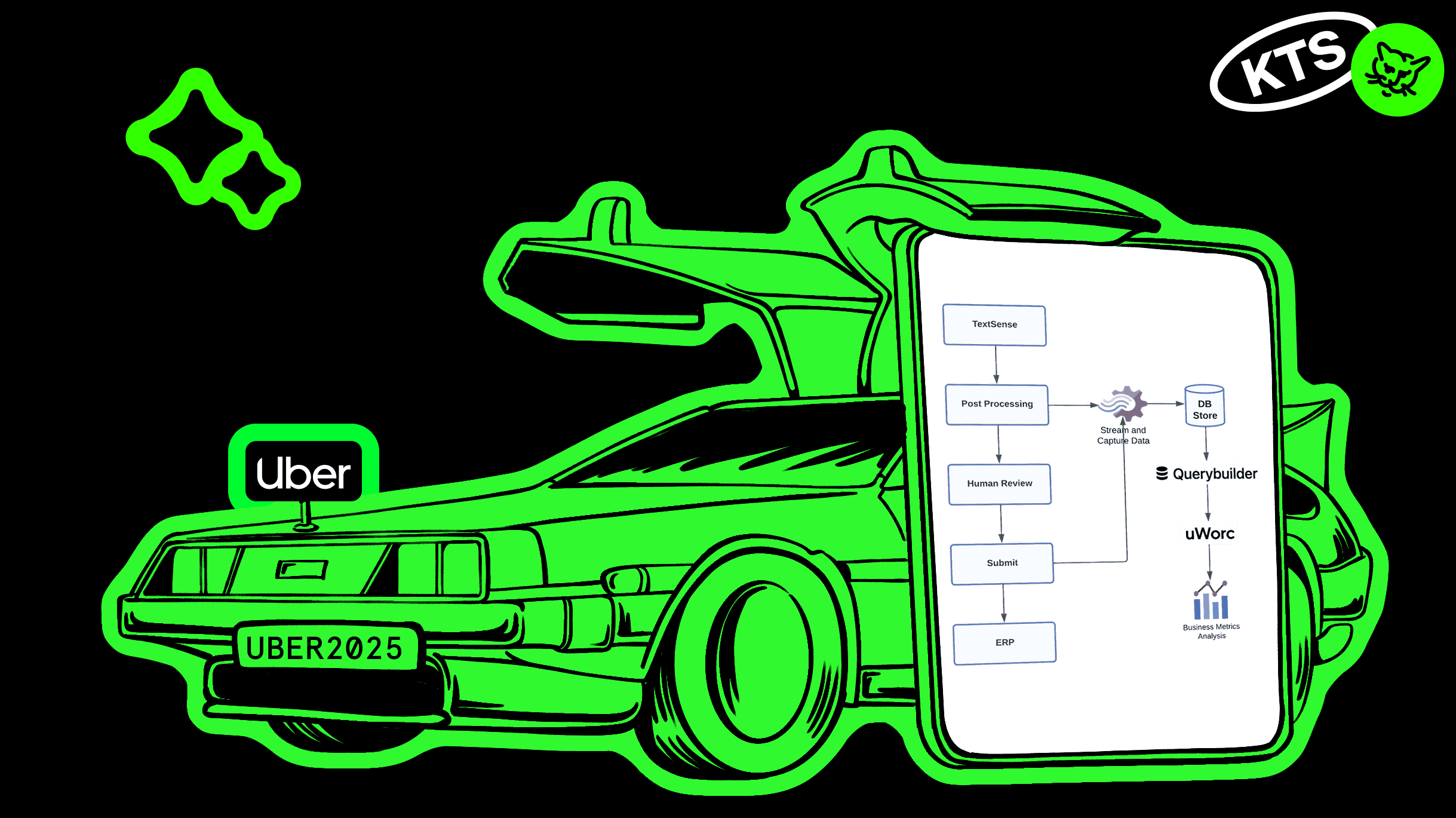
TextSense: масштабируемая корпоративная AI-платформа для обработки документов
Цель Uber заключалась в создании надёжной и гибкой платформы для обработки различных типов документов без необходимости вносить значительные изменения в код.
Команда Uber разработали модульную и расширяемую архитектуру, которая позволяет масштабировать платформу под разные сценарии: извлечение сущностей, суммирование, классификация. Особый упор сделан на конфигурацию, а не на код: адаптация под шаблоны конкретных стран выполняется через настройку, что значительно ускоряет внедрение.
Для управления сложными и разветвлёнными сценариями обработки документов использовали Cadence — собственную платформу Uber для построения надёжных бизнес-процессов. Также создали обширную библиотеку переиспользуемых компонентов для будущих интеграций.
Профилирование и разметка данных
Профилирование данных — ключевой этап в процессе извлечения информации из счетов. Оно необходимо для обучения LLM-моделей и повышения точности за счёт точной и последовательной разметки элементов данных. Создавая корректные и единообразные метки, мы помогаем модели лучше понимать структуру счёта.
Анализ базы поставщиков показал, что значительное количество счетов поступает от ограниченного круга компаний. Uber сделали приоритет на тех, кто генерирует наибольший объём счетов в год, особенно если точность извлечения данных для этих поставщиков опускается ниже заданного порога. Эти данные легли в основу стратегии по приоритизации разработки и развёртывания ML-моделей.
Поставщики, у которых точность на уровне отдельных полей не достигает минимального порога, отбираются для ручной разметки. Это позволяет модели обучаться и постепенно повышать точность извлечения. Команда Uber размечает ключевые поля счёта, такие как номер, дата, сумма и т. д. Такая разметка критически важна для улучшения понимания модели и обеспечивает стабильное качество извлечённых данных при последующей обработке.
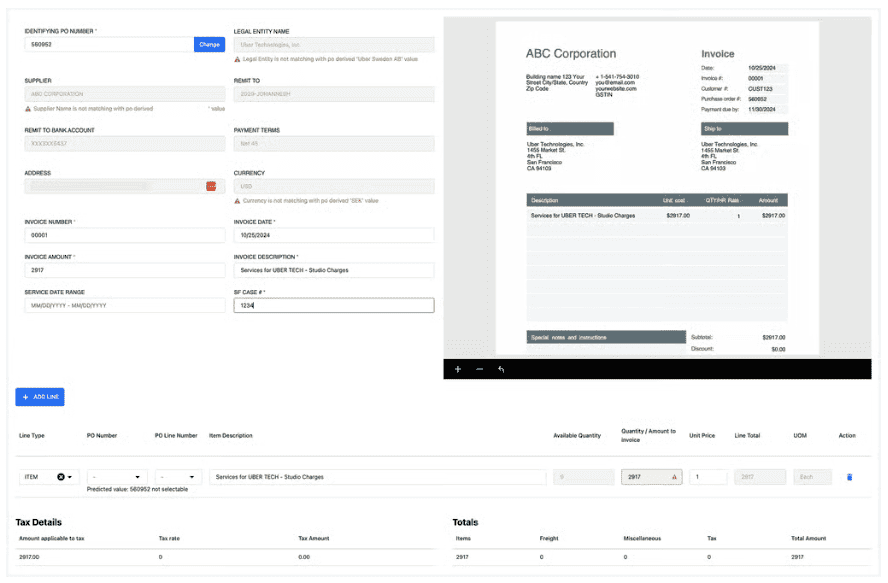
Дизайн пользовательского интерфейса (UI)
Uber спроектировали интерфейс, ориентированный на пользователей, выполняющих ручную проверку в рамках подхода HITL (Human in the Loop). Он позволяет сравнивать оригинальный PDF-документ и извлечённые из него данные в режиме «бок о бок».
Кроме того, в интерфейсе реализованы оповещения и предупреждения, чтобы все важные детали были сосредоточены в одном месте.
Это решение ускоряет процесс проверки: пользователю достаточно взгляда, чтобы оценить корректность данных, без необходимости переключаться между окнами или выполнять лишние действия.
Архитектура
TextSense: масштабируемая платформа для обработки документов
Uber разработал платформу TextSense — универсальное решение для обработки документов. Она абстрагирует все этапы процесса, описанные выше, и служит удобным инструментом для извлечения текста не только из счетов, но и из других типов документов. TextSense предоставляет модульный, переиспользуемый интерфейс поверх технологий OCR и LLM, что упрощает добавление новых сценариев через конфигурацию — без необходимости вносить изменения в код.
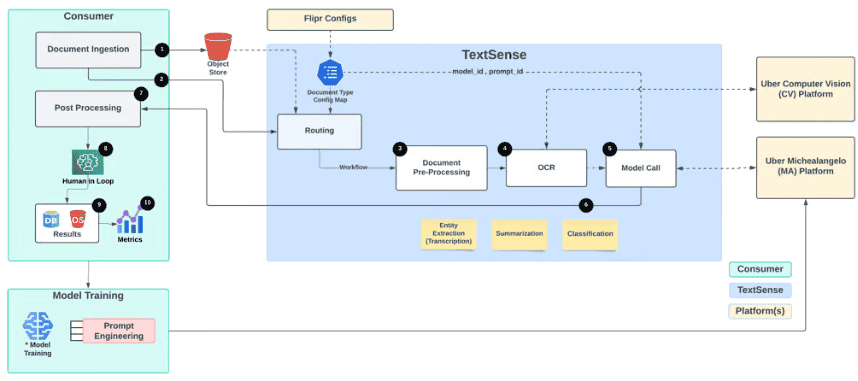
Этапы обработки документов
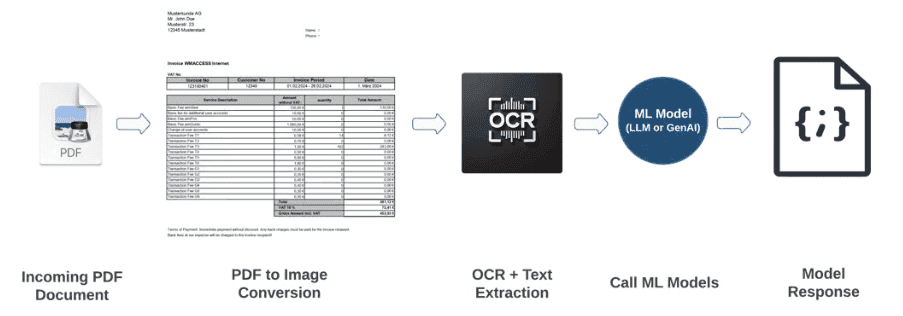
1. Загрузка документа
Интеграция с источниками: email, PDF-файлы, тикет-системы. Файлы сохраняются в объектном хранилище. Поддерживаются как структурированные, так и неструктурированные форматы.
2. Предобработка
Обработка изображений (улучшение сканов, распознавание рукописного текста), преобразование разных форматов (PDF, Word, изображения) в единый стандарт. Поддержка многостраничных документов.
3. Интеграция CV и OCR
Используется платформа Uber Vision Gateway для распознавания текста на изображениях документов.
4. AI и ML модели
Применяются обученные или дообученные LLM-модели для извлечения ключевых полей: номер счёта, дата, сумма и т. д. Модели постоянно улучшаются благодаря периодическому дообучению и обратной связи.
5. Постобработка и интеграция
Применяются бизнес-правила и пользовательские фильтры. После этого данные передаются в сторонние системы (например, ERP) для дальнейших действий.
6. Проверка данных и точность извлечения
Качество данных проверяется по базам или заранее заданным правилам. Важные поля дополнительно проходят HITL-проверку.
7. Метрики и мониторинг производительности
Фиксируются ключевые показатели: скорость обработки, точность, эффективность по затратам. Эти данные используются для постоянного улучшения системы.
Процесс обработки счетов с использованием TextSense
Процесс обработки счетов встроен во внутренние приложения Uber. Он интегрирован с платформой TextSense и позволяет обрабатывать PDF-файлы счетов, поступающих от поставщиков. Документы могут поступать двумя путями: через ручную загрузку PDF-файлов или через тикеты, созданные в тикет-системе.
- Ручная загрузка PDF-счетов. Пользователь загружает файл через веб-интерфейс. Фронтенд передаёт его на единый бэкенд-эндпоинт, который перенаправляет документ в TextSense для обработки.
- Интеграция с тикет-системой. Служба загрузки обрабатывает входящие тикеты: извлекает email поставщика и вложения (PDF-файлы). Текст письма передаётся в TextSense для парсинга ключевой информации, которая помогает в последующей обработке. Сами PDF-файлы вместе с извлечёнными данными также отправляются на бэкенд для дальнейшей обработки.
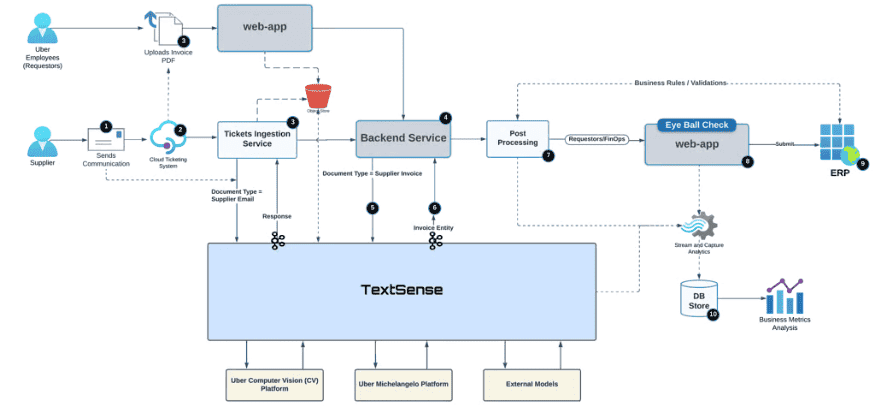
После того как TextSense извлекает данные из документа, в дело вступает постобработка. Она выполняет валидацию информации, обогащает её (при необходимости) и подготавливает к проверке человеком. После прохождения проверки и одобрения документы поступают в ERP-систему, где формируется платёж и производится оплата поставщику.
Оценка и выбор моделей
Работа с моделями начинается с подготовки обучающих данных, где в качестве «истины» выступают исторические данные по счетам и соответствующие им вложения.
Uber использовали два типа данных:
- Структурированные размеченные данные — поля из счетов, ранее внесённые в систему;
- Неструктурированные PDF-документы — извлечённый текст из оригинальных счетов.
Для обучения использовали данные за последний год, из которых 90% пошли на тренировку модели, а 10% — на тестирование.
Эти датасеты стали основой для дообучения открытых LLM-моделей. Uber протестировали и дообучили несколько моделей, включая seq2seq, Meta® Llama 2® и Google® Flan T5, чтобы найти наилучшее решение для наших задач по обработке счетов.
Модель T5 показала высокую точность (более 90%) при извлечении заголовков счетов, но плохо справлялась с табличной информацией: первая строка извлекалась корректно, но точность резко падала при переходе ко второй и последующим строкам. Несмотря на то, что дообучение помогло модели уловить шаблоны и бизнес-правила, оно также привело к галлюцинациям — вымышленным значениям, особенно в строках.
Также протестировали OpenAI® GPT-4, которая показала лучшие результаты по точности и адаптивности. Несмотря на то, что GPT-4 не «знала» шаблоны Uber, она уверенно извлекала информацию, присутствующую в документе, без выдумывания. Поэтому Uber построили пайплайн так, чтобы модель извлекала все возможные данные из счета, а бизнес-правила применялись уже на этапе постобработки, перед показом данных пользователю (в рамках HITL-проверки).
По результатам анализа модель GenAI оказалась очевидным победителем с точки зрения общей точности. Хотя open-source LLM показала немного лучшую точность по заголовкам, GenAI значительно опережала её в извлечении табличных данных (строк счета).
Uber планирует внедрить ансамблевый подход: объединение нескольких моделей в цепочку (model chaining) для повышения точности и адаптивности, особенно в сложных и нетипичных сценариях.
Методика расчёта точности
Оценка производительности модели GenAI — непростая задача, особенно в таких многоуровневых сценариях, как обработка счетов. Точность рассчитывается на двух уровнях:
Заголовочный уровень — общая информация о счёте (дата, номер, сумма и т. п.);
Построчный уровень — данные о каждой товарной позиции или услуге в счёте.
Для каждого поля определяем тип сравнения, необходимый для оценки точности:
- для однозначных данных, таких как номер счёта — требуется точное совпадение;
- для описательных полей, вроде названия услуги — допустимо нечёткое (fuzzy) сравнение строк.
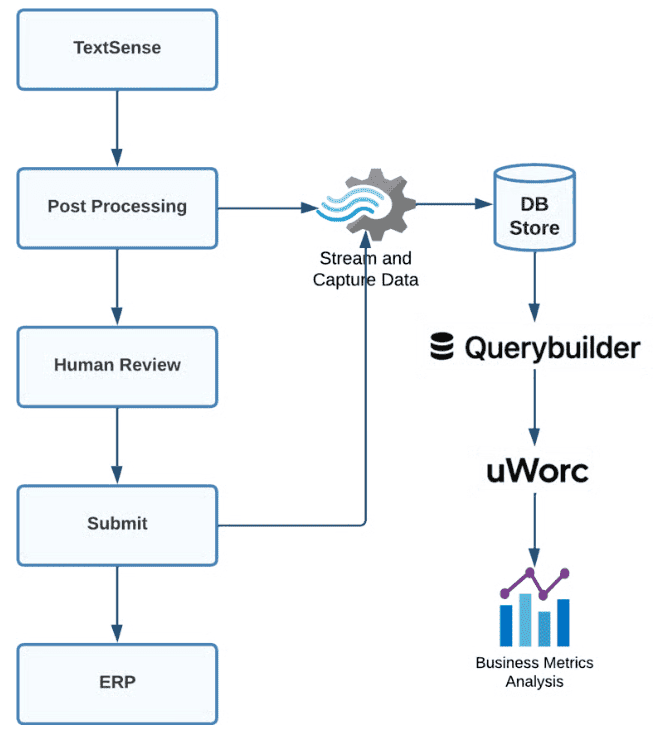
Uber разработали метрики, которые позволяют отслеживать точность в деталях — вплоть до уровня отдельных полей. Это помогает выявлять слабые места в работе модели и корректировать стратегии обучения. Команда также отслеживает динамику точности во времени, чтобы гарантировать, что модель не теряет качество по мере изменения шаблонов и увеличения объёма входящих данных.
Результаты
Внедрение системы автоматизации счётов на базе GenAI принесло впечатляющие результаты:
- Существенное снижение ручной работы — объём ручной обработки счетов сократился в 2 раза.
- Высокая точность — средняя точность модели составляет 90%. 35% всех счетов обрабатываются с почти идеальной точностью — 99,5%; ещё 65% — с точностью выше 80%.
- Сокращение времени обработки — среднее время обработки счёта снизилось на 70%.
- Улучшение пользовательского опыта — благодаря интеллектуальному извлечению данных из PDF, бизнес-правилам постобработки, удобному интерфейсу и надёжной интеграции с ERP-системой, процесс выставления и оплаты счетов стал значительно проще и быстрее.
Эти достижения задали новый уровень эффективности для финансовых операций Uber и позволили сократить затраты на 25–30% по сравнению с ручной обработкой.
Следующие шаги
Uber планирует продолжить развитие системы, сосредоточив усилия на повышении точности, расширении функциональности и создании слоя классификации документов.
Один из ключевых шагов — реализация полностью автоматизированной обработки от начала до конца для сценариев, где модель исторически демонстрировала 100% точность. Это позволит полностью исключить ручную проверку и ещё сильнее ускорить процессы.
А также развивать платформу TextSense, внедряя новые достижения в области ИИ и поддерживая её актуальность за счёт:
- регулярных обратных связей от пользователей,
- постоянного мониторинга производительности,
- интеграции с новыми корпоративными системами.
Uber планирует добавить классификационный слой, который позволит автоматически распознавать тип документа и направлять его в соответствующий процесс обработки.
Заключение
Команда преодолела ограничения ручной обработки, добилась значительного повышения эффективности и сократили издержки.
Однако стремление к инновациям не ограничивается обработкой счетов. Платформа TextSense уже сегодня служит основой для расширения автоматизации обработки других типов документов в рамках компании.
Интеграция технологий NLP и ИИ позволяет точно извлекать и валидировать данные, а подход Human-in-the-Loop (HITL) обеспечивает необходимый уровень контроля и соответствие требованиям.
Внедрение ИИ в корпоративные системы позволило Uber задать новый стандарт для автоматизации документооборота и invoice processing. Этот кейс показывает CTO и CIO, как generative AI помогает в цифровой трансформации закупок и финансовых процессов, снижая издержки и повышая точность.