Как мы проводим IT-аудит: живой кейс, инженерный подход и надежность без фанатизма

За годы работы мы сформировали свою практику для аудита инфраструктуры. Мы не придумали для нее громкого цепляющего названия, но это не мешает ей приносить пользу. Она стабильно помогает нам выявлять и устранять недостатки в «подкапотном пространстве» совершенно разных бизнесов.
Основная задача практики — напоминать нам, какие слои инфраструктуры чаще всего проектируются без должного внимания и приводят к возникновению серьезных рисков в дальнейшем. В этой статье Станислав Пьянов, DevOps-техлид в KTS, поделится этой практикой и покажет на примере недавнего кейса, как мы применяем ее.
Неважно, насколько ваша инфраструктура зрелая и развитая. Иногда очевидные пробелы мы обнаруживали даже у крупных заказчиков. Так что если при прочтении вы узнаете себя, рекомендуем не откладывать устранение недочетов в долгий ящик.
Договоримся о терминах
В статье будет довольно много абстрактных понятий, поэтому для начала я сформулирую наши определения для некоторых из них, чтобы избежать неправильных трактовок и расхождений в понимании.
- Под словом система мы подразумеваем множество элементов, находящихся в неких связях друг с другом, которое образует определенную целостность, единство.
- Под словом процесс — совокупность взаимосвязанных действий, направленных на достижение определенного результата.
- Под словом практика — набор правил и приемов, определяющих, как именно выполняются процессы и принимаются технические решения в повседневной работе.
Откуда растут ноги, и зачем вообще проводить аудит?
Для контекста расскажу чуть больше о нашей работе.
Мы — команда DevOps-инженеров, которая берет на себя полный цикл работы с инфраструктурой: от проектирования архитектуры с нуля до ее реализации, масштабирования и сопровождения. Мы автоматизируем все, что можно автоматизировать в рамках необходимого, чтобы ускорить процессы, снизить риски и повысить устойчивость систем. При этом мы не только создаем новую инфраструктуру, но и обеспечиваем безопасные миграции существующих решений — из онпремис-сред в облака, между облачными провайдерами или в обратном направлении.
К нам обращаются клиенты с разным уровнем зрелости инфраструктуры и процессов. Как правило, поводом для обращения становятся разрозненные проблемы и симптомы: система работает, но остается нестабильной и плохо прогнозируемой, происходят сбои, и иногда о них команда или бизнес узнают уже от пользователей.
Эти проявления часто воспринимаются как отдельные, несвязанные между собой сложности — проблемы в работе сопровождения, неудачная смена разработчиков или внезапное ухудшение стабильности. При этом в большинстве случаев за набором таких симптомов скрывается единая системная причина.
При отсутствии целостного подхода к развитию инфраструктуры и процессов в системе накапливаются устаревшие и слабо описанные компоненты. Даже после замены или утраты актуальности отдельных сервисов они нередко продолжают существовать в инфраструктуре, поскольку их влияние на архитектуру остается неочевидным. Это приводит к росту сложности и связанности системы, из-за чего любые изменения становятся рискованными и плохо прогнозируемыми, а нестабильность — системной.
Приходя на проект, мы в первую очередь формируем целостное представление о системе в целом: понимаем бизнес-контекст, архитектурные взаимосвязи между сервисами и то, как организованы процессы управления инфраструктурой. Такой подход позволяет нам не ограничиваться отдельными симптомами, а провести комплексный анализ — выявить точки отказа, узкие места, неустойчивые практики и потенциальные риски на уровне архитектуры и процессов.
Отдельное внимание мы уделяем вопросам безопасности. Хотя это не наша ключевая специализация, мы оцениваем зрелость процессов и фиксируем типовые уязвимости: излишне открытые порты, недостаточную защиту каналов связи, ошибки в управлении секретами или избыточные права доступа. В таких случаях мы даем обоснованные рекомендации и, при необходимости, предлагаем практичные способы устранения проблем своими силами.
Результатом аудита является четкая и структурированная картина текущего состояния системы и процессов, а также видение того, как будет выглядеть инфраструктура после реализации наших рекомендаций и какие преимущества это принесет. Это помогает клиентам навести порядок в архитектуре и управлении, избавиться от накопившихся рисков и определить приоритеты для дальнейших улучшений. В итоге создается надежная, управляемая и устойчивая IT-среда, поддерживающая рост бизнеса без хаоса и сбоев.
Практика проведения аудита
Но сначала еще немного терминов.
Под системным подходом мы понимаем комплексный разбор инфраструктуры и процессов как единого организма. Мы оцениваем не только отдельные компоненты, но и их взаимосвязи, влияние друг на друга, архитектурные принципы, на которых все построено, и то, как это отражается на устойчивости, безопасности и эффективности платформы.
Инженерный подход для нас — это сочетание глубокой технической экспертизы и практического опыта. Мы не ограничиваемся формальными чек-листами, а выявляем реальные слабые места, архитектурные дисбалансы, точки отказа и операционные риски. Наши рекомендации всегда основаны на инженерной логике и опыте эксплуатации — с прицелом на конкретный, реализуемый план действий.
При проведении аудита мы опираемся на широкий набор индустриальных подходов и практик надёжности и управления IT-системами. Мы осознанно не применяем отдельные фреймворки целиком «от А до Я», поскольку для малых и средних организаций это часто избыточно и не приносит практической ценности. Вместо этого мы подбираем и адаптируем конкретные принципы и практики с учетом архитектуры, масштаба и бизнес-задач клиента.
Наша практика состоит из пяти основных направлений анализа:
- Архитектура и компоненты инфраструктуры — фундамент, на котором строится устойчивость и управляемость системы.
- CI/CD процессы и управление изменениями — скорость и предсказуемость развития.
- Безопасность — работа с секретами, контроль доступа, защищенные каналы связи, сохранность данных.
- Мониторинг и логирование — видимость состояния и своевременное реагирование.
- Тестирование и проверка стабильности — уверенность в отказоустойчивости и масштабируемости.
Представленный перечень направлений анализа не является исчерпывающим, однако в большинстве случаев он достаточен для формирования объективной картины зрелости системы. Мы рассматриваем его как обязательный базис аудита, который при необходимости может быть расширен с учетом особенностей архитектуры, процессов и бизнес-контекста конкретной компании, но не сокращен. Ниже в статье я попробую на конкретном примере раскрыть каждое направление.
Аудит на примере живого кейса
К нам обратилась продуктовая компания, инфраструктура которой росла вместе с бизнесом в течении нескольких лет. На момент обращения команда сталкивалась с набором проблем, которые воспринимались как разрозненные, но на деле были симптомами одной и той же корневой причины — отсутствия выстроенных процессов и практик управления инфраструктурой:
- Нестабильность, которую сложно объяснить. Сбои происходили регулярно, но их причины каждый раз выглядели разными. Команда тратила время на тушение пожаров, а не на развитие.
- Инфраструктура, которую никто не видит целиком. Система разрослась, но полной и актуальной картины — что работает, как связано и зачем нужно — не было ни у кого.
- Каждый релиз — лотерея. Выкладки периодически ломали продакшен, откаты требовали ручных действий.
- Зависимость от конкретных людей. Знания о системе не были формализованы — с уходом или отпуском ключевых специалистов терялся контекст, который невозможно быстро восстановить.
- Безопасность, отложенная «на потом». Вопросы контроля доступа, изоляции и аудита действий откладывались как не приоритетные, но с ростом системы превращались в нарастающий риск.
Архитектура и компоненты инфраструктуры
Аудит мы начинаем с простого вопроса: «Сколько сервисов запущено в продакшене и кто за них отвечает?» Обычно четкого ответа нет — вместо него мы получаем устаревшие Excel-таблицы, схемы в Miro без описаний связей и актуального состояния или статью в документации, которая, как правило, безнадежно устарела. Здесь было так же.
Команда заказчика сказала прямо: «Мы изначально ориентировались на быстрый запуск, и все работало. Но временем мы стали тонуть в куче виртуалок и инцидентах» Нам скинули ссылку на схему архитектуры в draw.io — там обнаружились условные обозначения сервисов и наброски связей без объяснений и претензий на полноту.
Чтобы собрать реальную картину, пришлось провести серию многочасовых встреч с менеджерами и разработчиками.
Что обнаружили:
- Избыточность окружения: инфраструктура построена по принципу «один сервис — одна виртуалка». Так появилось больше 150 ВМ, которые сложно поддерживать и масштабировать.
- Ручные изменения без контроля: конфигурации частично автоматизированы через Ansible, но многое менялось руками. А еще машины, созданные временно для тестов, незаметно перешли в продакшен. Они не отражены в системе управления конфигурацией и нигде не задокументированы.
- Нет централизованного управления версиями: обновления сервисов выполняются вразнобой, без логирования и возможности отката. При сбоях цепочку изменений восстанавливали по памяти, буквально опрашивая коллег.
- Нарушение сетевой изоляции: все сервисы общаются между собой через публичные IP-адреса, никаких приватных сетей.
- Единые точки отказа: критические компоненты (БД, файловое хранилище) работали без репликации и изоляции. Любой сбой бил по всему сразу.
Общая картина: системного управления архитектурой нет. Знания фрагментированы, процессы не описаны, а устойчивость держится на конкретных людях, а не на практиках.
Что мы сделали:
- Кластерная архитектура вместо зоопарка ВМ: разрозненные виртуалки заменили на Kubernetes-кластер с описанными манифестами, namespace-изоляцией и управляемым жизненным циклом сервисов.
- Infrastructure as Code: внедрили Terraform, Helm и Argo CD для декларативного управления инфраструктурой и приложениями. Все версионируется и отслеживается. Инструменты подстроены под процесс — каждая фаза (деплой, обновление, откат) управляется как часть единой практики.
- Отказоустойчивая база данных: монолитную БД MySQL заменили на управляемый MySQL-кластер с репликацией и автовосстановлением в Yandex Cloud.
- Сетевая безопасность: приняли ряд мер по изоляции ресурсов и повышению безопасности.
- Актуальная архитектурная схема: создали и поддерживаем структурированную карту инфраструктуры — все критические связи, точки отказа и зависимости на виду.
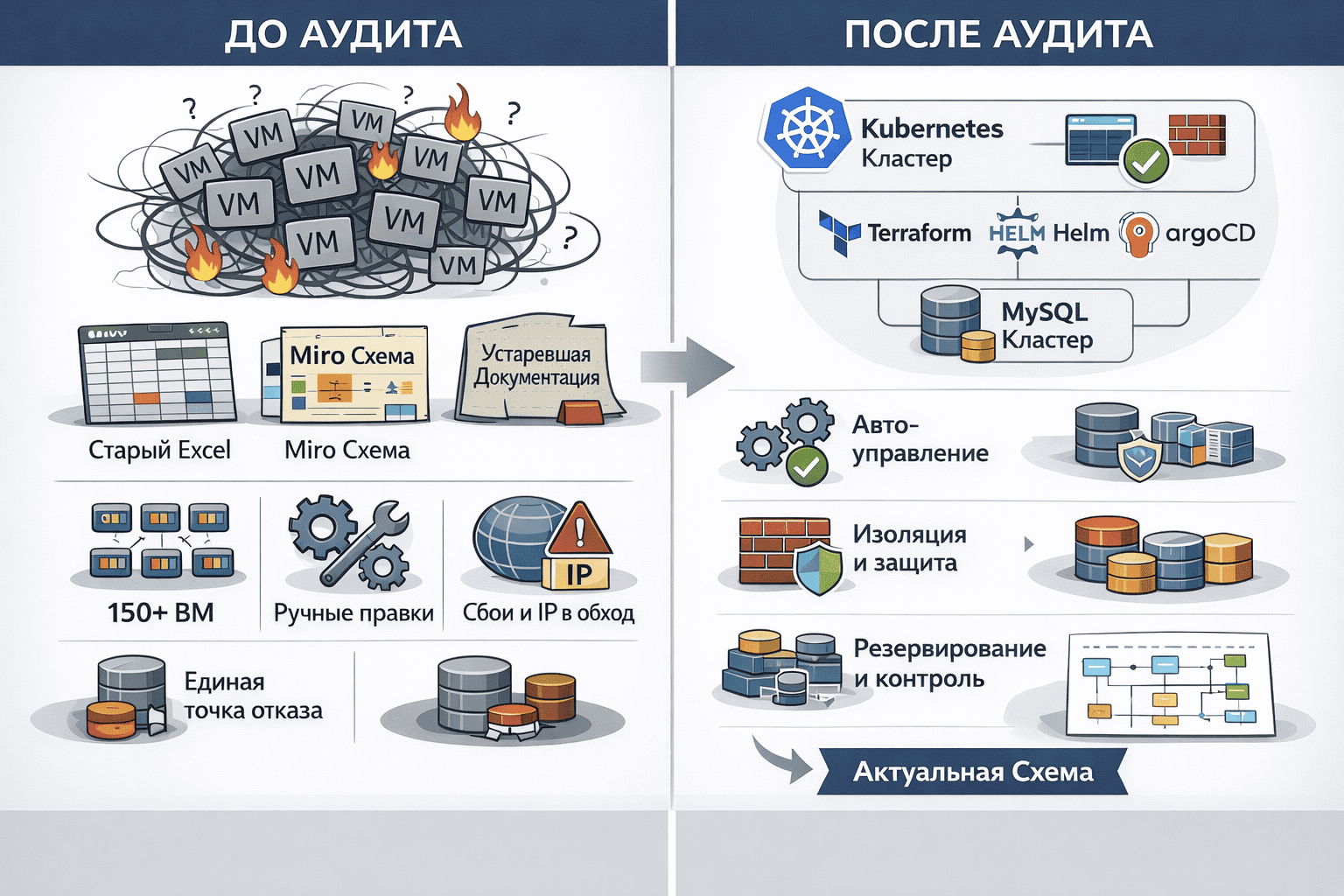
После этих изменений инфраструктура стала управляемой и предсказуемой. Сопровождение перестало зависеть от «героев», которые помнят, где что лежит — теперь все описано и воспроизводимо.
CI/CD процессы и управление изменениями
Здесь мы начали сразу двух вопросов: «Как вы катите в прод?» и «Как откатываете?». Ответ был таким: «Используем GitLab, при пуше в релизную ветку срабатывает пайплайн. Если нужно откатить — заходим по SSH, правим docker-compose.yml, подставляем предыдущую версию контейнера из registry и делаем docker-compose up»
До аудита процесс выглядел так:
Что обнаружили:
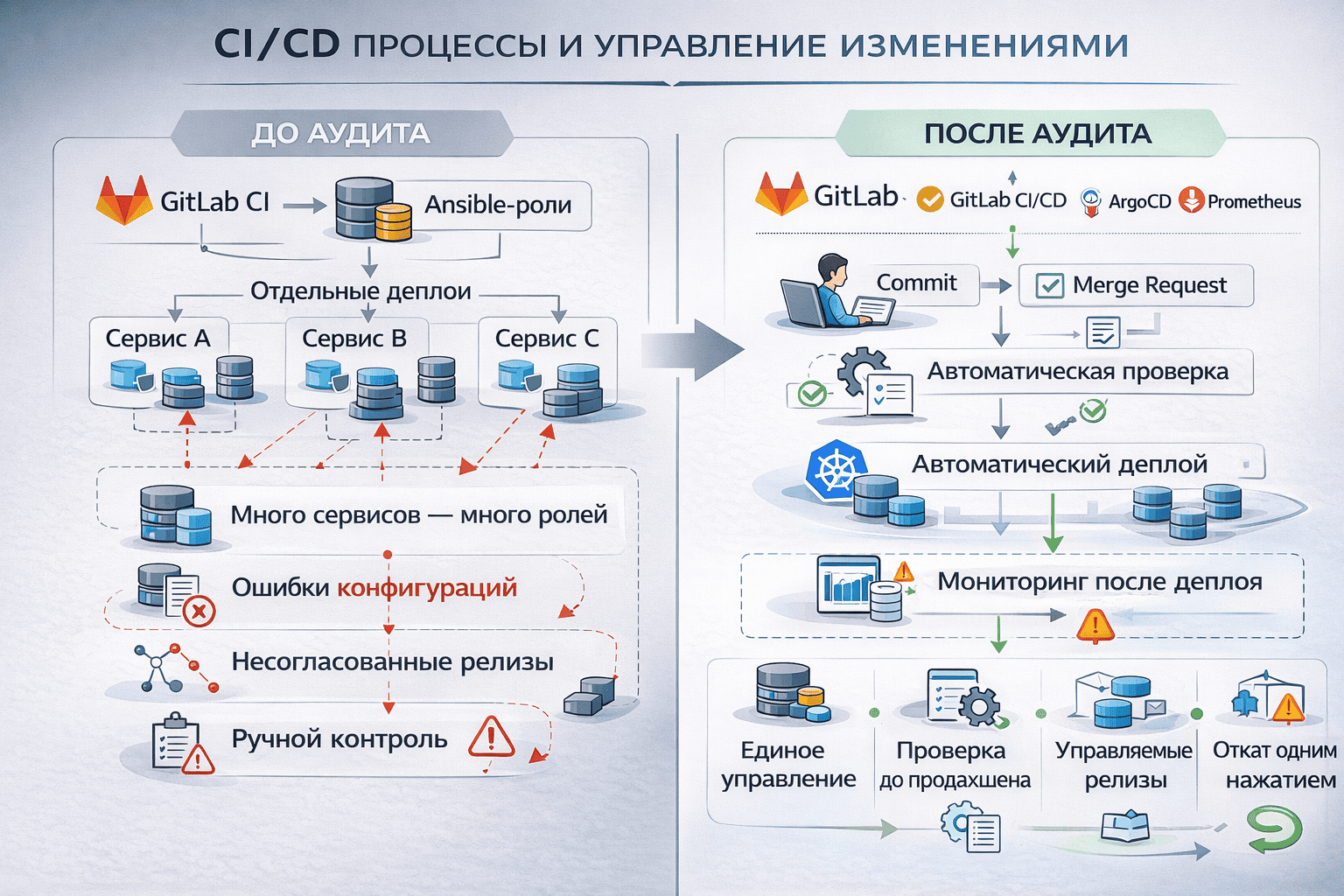
- Деплой происходит через пайплайн GitLab CI, который дергает отдельный репозиторий с Ansible-ролями. Роли незамысловатые: достать секреты из registry, docker-compose down, docker-compose up. При этом для каждого сервиса есть отдельная роль, хотя логика у всех одинаковая.
- Пайплайны работают нестабильно: контейнеры то не останавливаются, то не стартуют. Например, когда деплой упал на шаге docker-compose up, один из инженеров нашел опечатку в docker-compose.yml и вручную поправил ее на проде, а в код это не попало. На следующем релизе все опять сломалось, пришлось заново искать ошибку.
- Связки между CI и мониторингом нет. О сбое в продакшене узнают не из алертов, а от пользователей или от разработчиков, которые зашли по SSH, чтобы проверить итог релиза, и заметили проблему.
По сути, весь процесс держался на памяти конкретных людей, а не на системе. Ни GitOps, ни нормального версионирования, ни автоматических проверок. Выкладка непредсказуемая, история изменений разбросана, а об инцидентах узнавали только тогда, когда они уже влияли на бизнес.
Что мы сделали:
Собрали прозрачный процесс доставки изменений от коммита до автоматического отката, без SSH-доступа к продакшену и ручных правок. Так как задача была не «навернуть сложный пайплайн», а выстроить минимальный, но достаточный процесс с инженерным обоснованием каждого шага, в итоговый пайп вошло только то, что снижает риск ошибок, повышает управляемость или делает процесс воспроизводимым. Все остальное мы сознательно выкинули.
- Внесение изменений в код: любое изменение начинается с коммита. Никаких правок на продакшене, зафиксирован единый версионируемый источник истины.
- Merge request — точка фиксации и минимальный контроль. Можно обсудить правки, проверить целесообразность, зафиксировать решение о выкладке.
- Автоматическая проверка конфигураций: система сама валидирует конфигурации, манифесты и шаблоны деплоя. Ошибки ловятся до продакшена, человеческий фактор исключен.
- Автоматический деплой через CI/CD и GitOps, без SSH и ручных действий. Процесс воспроизводимый и не зависит от знаний конкретного инженера.
- Мониторинг после деплоя: успешность определяется не статусом пайплайна, а реальным состоянием системы. Метрики и алерты подтверждают, что сервисы работают в заданных пределах.
- Откат является частью того же процесса, что и деплой. Выполняется теми же инструментами (GitLab + ArgoCD), по тем же правилам (MR), быстро и без дополнительных рисков.
В итоге хаотичный ручной деплой превратился в процесс с единым набором правил. Каждый шаг прозрачен и воспроизводим, MTTR сократился, а риск бизнес-сбоев из-за кривой выкладки снизился.
Безопасность
Начали с проверки сетевой доступности и контроля доступа. Причина большинства неприятных находок в данном домене типичная: на старте никто об этом не задумывался (a.k.a. «так исторически сложилось»).
Что обнаружили:
- Отсутствие сетевой изоляции: Kafka, базы данных и виртуальные машины общались между собой через публичные IP-адреса без каких-либо правил ограничения доступа.
- Общие учетные данные: одни креды на всю команду, ролевой модели доступа нет в принципе.
- Нет централизованной аутентификации: ни VPN, ни SSO, ни аудит-логов.
- Непроверенные бэкапы: формально бэкапы были, но их выполнение и работоспособность никто не проверял. Бэкап, который не проверен — это не бэкап, а надежда.
Безопасность — это тоже полноценная практика из многих составляющих: кто имеет доступ и почему, как этот доступ контролируется, какие действия логируются и кто за что отвечает. Если эта практика не выстроена, любые точечные меры остаются заплатками, которые рано или поздно перестанут работать.
Что мы сделали:
- Сетевая изоляция: сервисы общаются только внутри приватной сети, SSH — исключительно через VPN (Firezone), прямого доступа извне больше нет.
- Централизованная аутентификация и управление доступом: внедрили Keycloak (SSO) и IAM с ролевыми политиками. У каждого пользователя свои учетные данные и права, соответствующие его роли.
- Аудит действий: все подключения и изменения логируются. Видно, кто, когда и что делал.
- Анализ кода и образов: встроили в CI/CD статический анализ кода и сканирование собранных Docker-образов на известные уязвимости. Потенциальные проблемы выявляются до попадания в продакшен, а не после.
- Бэкапы — под контролем: автоматизировали выполнение бэкапов, настроили алерты на их отсутствие. Ввели регламент тестирования бэкапов с заданной периодичностью. Полная автоматизация проверки восстановления требовала значительных трудозатрат и на данном этапе не была реализована, но задача зафиксирована в бэклоге.
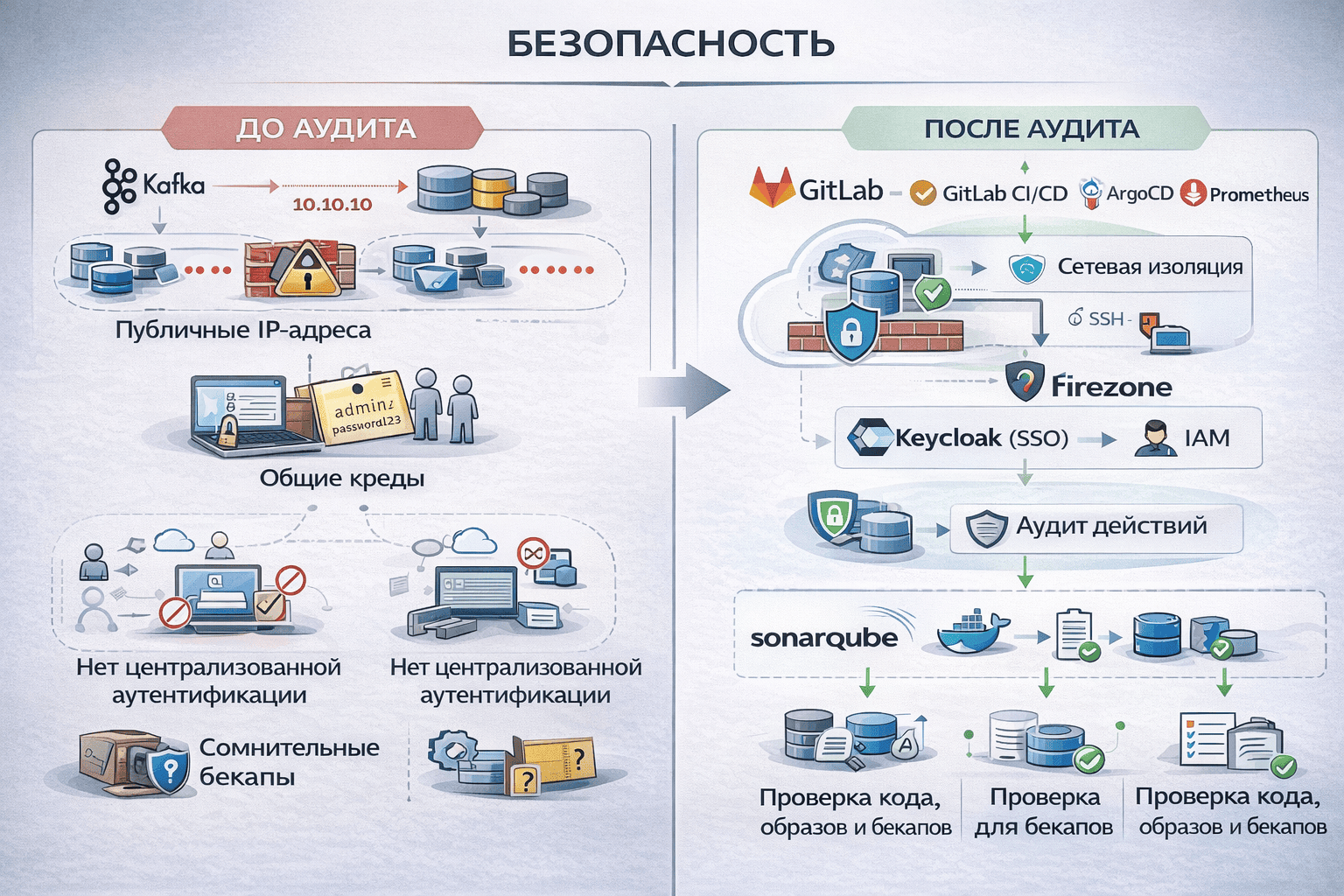
Теперь четко понятно, кто, зачем и с какими правами подключается к системам. Это снизило риск случайных и несанкционированных изменений, упростило управление привилегиями и сделало работу с доступами предсказуемой.
Мониторинг и логирование
Стек мониторинга и логирования формально существовал, но своей функции не выполнял — не помогал ни понимать состояние системы, ни принимать решения. Про SLO (Service Level Objectives) команда не слышала, а идея описывать надежность в измеримых цифрах воспринималась как что-то лишнее. Типичный диалог с бизнесом:
— Как работает система?
— В целом нормально, но иногда бывают сбои.
— А сколько сбоев, как долго и кто пострадал?
— Ну там это… Иногда бывают, говорю же. Время от времени.
В общем, метрика простая: если никто не жалуется, значит, система работает. О реальном состоянии сервисов можно только догадываться.
Что обнаружили:
- Мусорные метрики: что-то собиралось в Zabbix, даже нашлись какие-то дашборды, но это был набор разрозненных графиков без привязки к сервисам и бизнес-критичности. Создавались они разными людьми в разное время и не отвечали на главные вопросы: что деградирует, насколько это серьезно, нужно ли вмешиваться. Инженеры ими просто не пользовались.
- Неструктурированные логи: частично поступали в Graylog, но без единого формата и привязки к конкретным сервисам. Искать по ним можно было только со знанием внутренностей системы, и использовались они уже постфактум, когда инцидент очевиден. Для ранней диагностики это не работало.
- Мусорные алерты приходили в мессенджеры без приоритизации и контекста. Все выглядели одинаково, с непонятным уровнем критичности. В итоге они превращались в фон, который читали разве что от скуки. Реакция на реальные проблемы зачастую наступала уже после жалоб от пользователей.
Проблема была не в инструментах, они-то были. Не было модели наблюдаемости: мониторинг не привязан к архитектуре, к критичным сервисам, к пользовательским сценариям. Он не отвечал на вопросы «что сломалось», «насколько это важно» и «кто должен реагировать».
Что мы сделали:
- Определили, что и зачем мониторить: выделили критичные компоненты и сервисы, собрали требования по доступности и нагрузке, задали начальные SLO (например, доступность ключевого сайта 99,9% в месяц, время реакции на инцидент ≤ 15 минут). Построили соответствующие дашборды.
- Собрали стек под задачу: VictoriaMetrics для метрик по ключевым SLI (latency, error rate, saturation), Grafana + Loki — единая панель для метрик и логов, Alertmanager — маршрутизация алертов по severity и ответственности, S3 для долговременного хранения логов. Все дашборды и алерты описаны как код и контролируются через Git и CI.
- Настроили реагирование и эскалацию: инциденты классифицируются по критичности, в соответствии с этим настроены алерты. Ведется лог инцидентов и постмортем-анализ, эскалация происходит только после первичной диагностики. SLO стали основой для принятия решений.
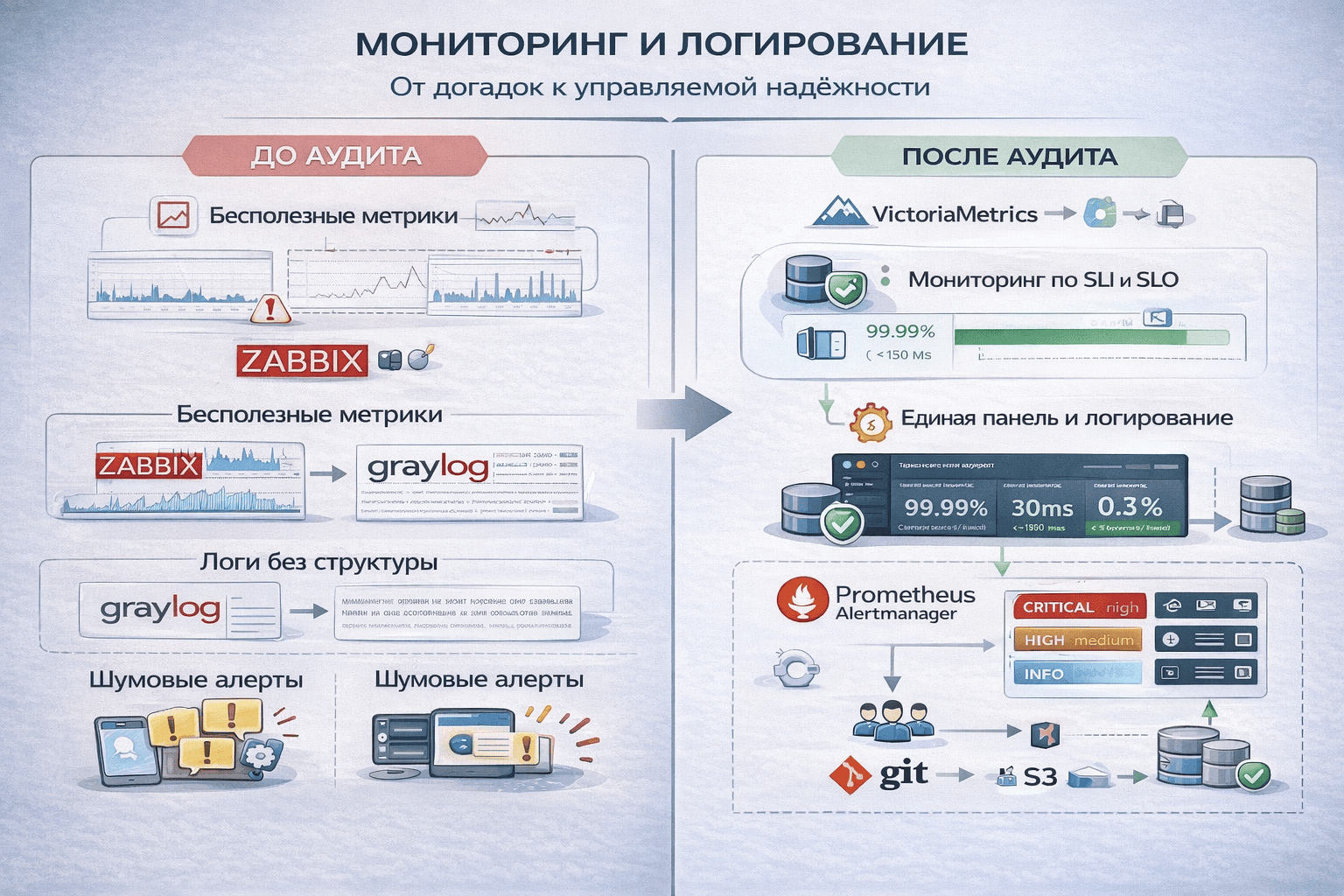
Мониторинг превратился из разрозненного набора несвязанных дашбордов в рабочий инструмент. Команда видит, что происходит, понимает приоритет и знает, кто и как должен реагировать. Надежность перестала быть субъективным ощущением — она измеряется и управляется.
Тестирование и проверка стабильности
Раз уж заговорили о надежности, стоит вспомнить и о том, как ведут себя сервисы под нагрузкой и при сбоях. До аудита тестирование сводилось к ручным проверкам отдельных компонентов без автоматизации. Как система поведет себя при реальном инциденте, никто не знал.
Что обнаружили:
- Нет тестовых окружений: проверки проводились на продакшене или не проводились вовсе. Отдельных стендов для нагрузочного тестирования не существовало.
- Нет данных о поведении под нагрузкой: предельные характеристики компонентов неизвестны, масштабируемость не проверялась.
- Реактивный подход к сбоям: узкие места находили уже после инцидентов. Проверка стабильности зависела от инициативы конкретных инженеров, а не от процесса.
Что мы сделали:
- Тестирование на изолированных стендах. Подняли динамические тестовые окружения для разработчиков и тестировщиков, а также отдельные стенды, идентичные продакшену, для оценки производительности, моделирования роста нагрузки и поиска узких мест до того, как они дадут о себе знать в реальных условиях.
- Боевые тесты при минимальной нагрузке. В часы минимального трафика проводили контролируемые сценарии прямо в продакшене: имитация скачков нагрузки, отказов подсистем, отключение отдельных компонентов. Это позволило найти реальные точки отказа и устранить их до того, как они стали инцидентами.
- Chaos Engineering. Внедрили выборочные отключения сервисов, имитацию потери сети, переполнения очередей и зависаний БД. Это помогло выяснить, какие сервисы восстанавливаются автоматически, где нет retry-логики или таймаутов, и какие зависимости критичны, но не задокументированы.
- Метрики стабильности. После каждого теста добавляли новые SLI, расширяли дашборды, настраивали алерты. Мониторинг стал продолжением практики тестирования, а не отдельной системой.
В итоге тестирование стабильности встроено в повседневную работу команды. Инженеры знают, как система ведет себя при стрессе, изменения перестали быть источником страха, а реакция на инциденты стала предсказуемой и документированной.
Вывод
Каждое направление аудита — архитектура, CI/CD, безопасность, мониторинг, тестирование стабильности — это не изолированная задача, а часть единой цепочки создания ценности для бизнеса. Мы сознательно выстраиваем работу так, чтобы улучшения в каждом направлении усиливали друг друга: управляемая архитектура делает деплой предсказуемым, прозрачный CI/CD снижает риск инцидентов, наблюдаемость ускоряет реагирование, а тестирование стабильности подтверждает, что система действительно выдержит нагрузку.
В этом кейсе мы прошли путь от хаотичной инфраструктуры с ручными процессами до формализованной системы управления. Конкретные инженерные шаги (переход на Kubernetes и IaC, внедрение GitOps, выстраивание ролевой модели доступа, построение мониторинга с SLO, запуск нагрузочного и хаос-тестирования) стоят за измеримыми результатами: повышением стабильности, сокращением времени восстановления, снижением операционных рисков и расходов на сопровождение.
При этом внедренные изменения закрепились именно как практики и процессы, а не как разовые исправления. Управление доступами, наблюдаемость, доставка изменений, тестирование — каждое направление теперь работает как часть системы и не зависит от знаний отдельных людей. Это то, что позволяет инфраструктуре развиваться вместе с бизнесом, а не становиться его ограничением.
Если ваша инфраструктура проявляет похожие симптомы, задайте себе те же вопросы, которые мы задаем заказчику. Вполне вероятно, что предложенная нами практика поможет вам взглянуть на свою систему комплексно, а не прикладывать подорожник к отдельным выстреливающим проблемам.